Large-scale data processing with Couchbase Server and Apache Spark
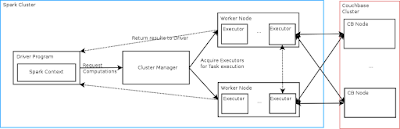
I just had the chance to work a bit with Apache Spark. Apache Spark is a distributed computation framework. So the idea is to spread computation tasks to many machines in a computation cluster. The idea here is to load data from Couchbase, process it in Spark and store the results back to Couchbase. Couchbase is the perfect companion for Spark because it is capable to handle huge amounts of data, provides a high performance (hundreds of thousands ops per second / sub-milliseconds latency) and is horizontally scalable by also being fault tolerant (replica copies, failover, ...). You might already know Hadoop for this purpose. Sparks approach is similar but different ;-). In Hadoop you typically load everything into the Hadoop distributed file system and then let process it 'co-located' in parallel. In Spark each worker node is processing the data by default in memory. Your data is described by a R(esilient) D(istributed) D(ataset). Such an RDD is in the first step not the data